Ce qu’il faut pour construire une IA vraiment efficace dans le support client (Aperçus du responsable IA de Hiver)



Perspectives du responsable IA de Hiver
La plupart des gens pensent que développer des fonctionnalités d’IA pour une plateforme de service client se résume à planifier, exécuter et mettre en production.
Mais si vous parlez aux personnes derrière le rideau, vous comprendriez à quel point la réalité est différente.
Anurag Maherchandani, responsable IA chez Hiver, fait partie de ces personnes. Chez Hiver, une plateforme de service client propulsée par l’IA et utilisée par plus de 10 000 équipes de support pour gérer les conversations clients à grande échelle, la pression pour « ajouter de l’IA » est arrivée tôt et avec force. Chaque boîte de réception, chaque ticket, chaque interaction client semblait un candidat évident à l’automatisation.
 , responsable IA chez Hiver, fait partie de ces personnes. Chez
, responsable IA chez Hiver, fait partie de ces personnes. Chez {kind=link}
Anurag dirige toutes les initiatives IA de Hiver, ce qui signifie qu’il est responsable de déterminer quoi construire, comment le mettre en œuvre et pourquoi cela devrait compter pour les clients. Voici son point de vue sur ce qu’il faut vraiment pour développer des fonctionnalités IA efficaces.
Commencez par le résultat, pas par le modèle
Le principe fondamental derrière chaque décision d’IA chez Hiver : L’IA n’est pas le produit. Le résultat est le produit.
En pratique, cela signifie que le point de départ pour toute fonctionnalité IA n’est jamais « que peut faire ce modèle ? » mais plutôt « sur quelles décisions les humains passent-ils du temps alors qu’ils ne devraient pas avoir à le faire ? »
Cette distinction influence tout ce qui suit, du choix du problème à la façon dont la fonctionnalité est affichée dans l’interface utilisateur.
« Lorsqu’une équipe affirme qu’elle ‘construit un produit IA’, elle veut généralement dire qu’elle a intégré un modèle, l’a exposé via une interface, et atteint des niveaux de précision élevés. Mais rien de tout cela ne garantit de la valeur. Les utilisateurs n’achètent pas de l’intelligence. Ils achètent du soulagement : des tâches répétitives, de l’incertitude, de la friction opérationnelle », explique Anurag.
Même si un modèle semble excellent lors des tests, le véritable test décisif est de savoir s’il influence réellement la manière de travailler des utilisateurs.
Inférence ou règles : choisissez d’abord le bon outil
Avant qu’un problème n’atteigne l’étape du choix du modèle ou de l’évaluation des données, une question plus fondamentale s’impose : Est-ce que cela nécessite réellement de l’inférence ?
L’inférence signifie que le système doit généraliser à partir de schémas qu’il n’a pas explicitement vus, prendre des décisions qui ne peuvent pas être entièrement définies à l’avance.
Utiliser des règles signifie que la logique peut être écrite explicitement : si X, alors Y. Les deux approches ne sont pas interchangeables, et avoir recours à l’inférence là où des règles suffiraient ajoute du coût, de la latence, et de l’imprévisibilité sans valeur ajoutée.
Lorsque l’équipe de Hiver a eu besoin de configurer un routage pour les e-mails issus de certains segments de clients comme les comptes VIP, certaines industries, ou des domaines spécifiques, l’instinct initial était de développer un modèle d’IA capable de les reconnaître automatiquement.
Au lieu de cela, Hiver a créé des objets de règles configurables. Ceux-ci utilisent une logique explicite basée sur les domaines, les mots-clés et les métadonnées. Le résultat est prévisible, facile à déboguer et configurable par les utilisateurs finaux sans avoir à impliquer l’équipe IA de Hiver.
Par exemple, si une entreprise souhaite que tous les e-mails provenant de @enterprise.com ou les messages contenant le mot « contrat » soient envoyés vers une boîte prioritaire, elle peut mettre en place la règle en quelques minutes. Cela ne nécessite aucune IA, et il n’y a aucune ambiguïté dans la façon dont les e-mails sont gérés.
Comme le dit Anurag : « Si vous pouvez écrire les règles, écrivez les règles. Gardez l’IA pour les problèmes où écrire toutes les règles serait impossible, lorsque le système doit généraliser à partir de modèles qu’il n’a pas explicitement rencontrés. »
Évaluer les problèmes qui nécessitent vraiment de l’inférence
Lorsqu’un problème exige véritablement de l’inférence, Hiver l’évalue selon quatre critères avant de s’engager dans le développement :
- Fréquence. L’IA engendre de véritables surcoûts : coût d’inférence, latence supplémentaire et modes d’échec imprévisibles. Cette surcharge ne se justifie que lorsque la tâche est suffisamment fréquente pour que l’automatisation produise un effet cumulatif. Une tâche exécutée quelques fois par semaine justifie rarement une telle complexité. Une tâche effectuée des centaines de fois par jour par les agents, oui.
- Prévisibilité. Certaines classifications reposent sur des informations présentes dans l’entrée (contenu de l’email, objet, métadonnées), plutôt que sur l’apprentissage à partir de données disponibles. D’autres nécessitent un contexte que le modèle ne possède tout simplement pas : niveau du client, politiques d’escalade internes, jugement des agents acquis avec l’expérience. Avant de s’engager dans le développement, l’équipe vérifie la faisabilité en effectuant des tests sur les données historiques pour déterminer si une prédiction est même possible avec un niveau de confiance utile. Lorsqu’il n’y a pas de signal, aucune décision d’architecture n’y changera rien.
- Demande client. Résout-on un problème explicitement nommé par le client ou un que l’équipe suppose exister ? Dans le premier cas, les chances d’adoption sont bien supérieures. Dans le second, on obtient souvent des fonctionnalités qui fonctionnent bien mais qui sont ignorées lors du déploiement.
- Enjeux et réversibilité. Que se passe-t-il lorsque le modèle se trompe ? Une étiquette mal classifiée qu’un agent peut corriger d’un simple clic n’a pas du tout le même impact qu’une réponse incorrectement envoyée à un client ou qu’une escalade manquée. Les prédictions à faible enjeu, facilement réversibles, sont d’excellentes candidates à l’automatisation. Les décisions à fort enjeu nécessitent soit une validation humaine, soit un niveau de confiance nettement supérieur avant tout déclenchement.
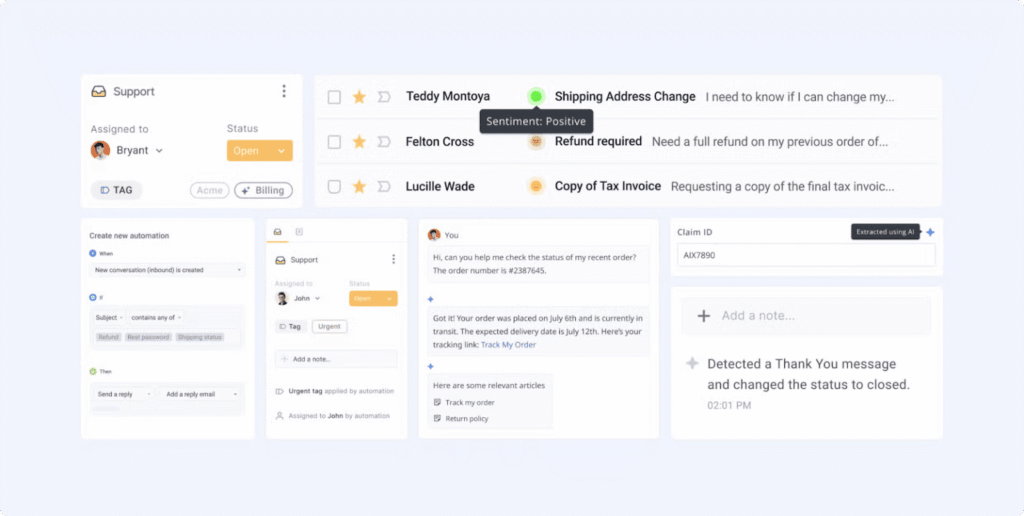
La fonctionnalité d’auto-étiquetage de Hiver fonctionne car elle satisfait aux quatre critères. Elle utilise un modèle pour déduire l’étiquette la plus pertinente pour une conversation entrante. Les agents n’ont plus à catégoriser chaque ticket manuellement.
Les équipes définissent un ensemble d’étiquettes dans le panneau d’administration, comme « Facturation » ou « Support technique. » Celles-ci servent de cibles de prédiction. Le modèle apprend les schémas à partir du contenu de l’e-mail, de l’objet et des métadonnées. Seules les étiquettes signalant un motif clair sont incluses.
Les agents accomplissent cette tâche sur presque chaque conversation, ce qui en fait une activité à haute fréquence. Le signal est présent dans le contenu des e-mails pour les étiquettes retenues, ce qui garantit la prévisibilité. Les clients de Hiver ont explicitement demandé de réduire la gestion manuelle, favorisant ainsi l’adoption. Lorsque le modèle se trompe, l’étiquette peut être corrigée d’un clic, ce qui minimise les conséquences et assure la réversibilité.
L’analyse de sentiment suit la même logique. Elle analyse le ton de chaque conversation afin d’identifier si un client est frustré, neutre ou satisfait. Les équipes y sont confrontées sur chaque conversation, donc la fréquence est élevée. Le ton est présent dans le texte, ce qui le rend prédictible.
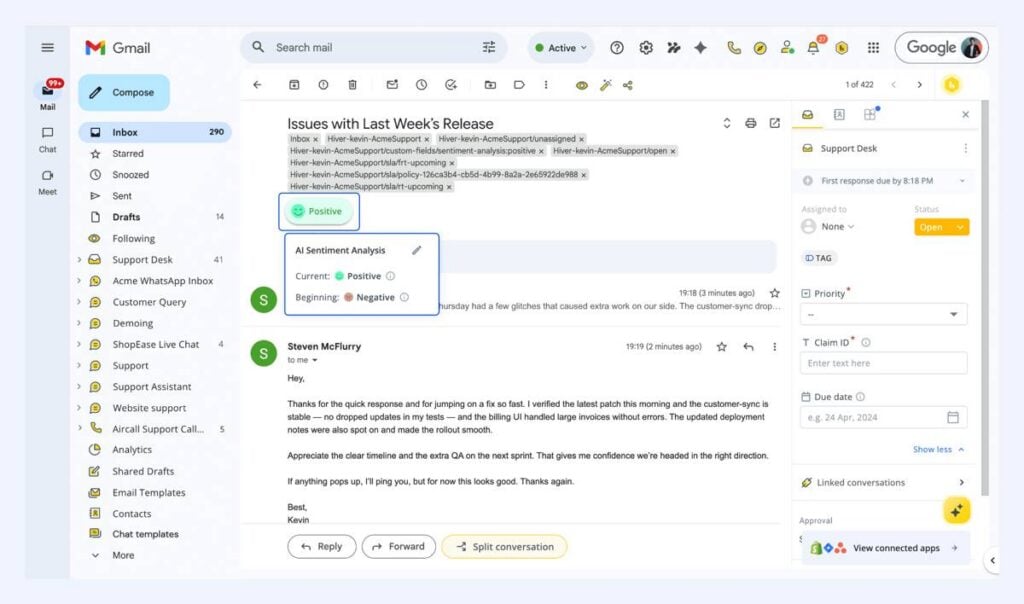
Les équipes souhaitent pouvoir repérer rapidement les clients frustrés, ce qui génère une demande affirmée. Si le modèle se trompe, les agents peuvent passer outre sans impact sur le résultat, ce qui limite le risque.
Tests de faisabilité avant le développement
L’une des étapes les plus exigeantes du processus de Hiver : mener des tests de faisabilité en matière de précision avant d’écrire la moindre ligne de code de production.
La fonctionnalité de suggestion d’étiquette est un exemple instructif. Ainsi, lorsqu’un e-mail indique « J’ai été facturé deux fois », le modèle doit sélectionner « Facturation. » Mais il essayait également de proposer des étiquettes comme « Client VIP » ou « Escalader vers le manager », qui ne peuvent pas être déduites à partir du simple e-mail. La précision était faible, et les agents ont cessé de faire confiance au résultat.
Le problème sous-jacent était l’incapacité à distinguer les types d’étiquettes prévisibles de celles qui ne le sont pas. Les catégories comme « Facturation », « Support technique », et « Retours » sont rattachées à des schémas linguistiques dans le contenu de l’e-mail. Elles sont apprenables.
Les étiquettes opérationnelles comme « Client VIP », « En attente du service juridique » et « Escalader vers le manager » dépendent d’un contexte externe : historique du compte, règles internes, coordination entre équipes. Aucun modèle entraîné uniquement sur les e-mails clients ne pourra les prédire de manière fiable.
La correction apportée fut structurelle : avant qu’un type d’étiquette ne soit intégré comme cible de prédiction, il passe par une vérification de faisabilité. Les données historiques permettent-elles de prédire de façon fiable ce résultat ? Si ce n’est pas le cas, il est exclu du périmètre du modèle, peu importe l’intérêt théorique de son automatisation.
« La discipline consistant à dire ‘ce type d’étiquette n’est pas un bon candidat pour l’automatisation’ a été plus difficile à acquérir que de construire le modèle. Mais cela nous a permis de ne livrer que des prédictions sur lesquelles les agents pouvaient compter. »
Intégrer l’IA dans le flux de travail, et non en amont
L’endroit où intervient l’IA dans le produit compte autant que ce qu’elle réalise.
Une fonctionnalité qui oblige les utilisateurs à s’arrêter, taper une consigne, puis vérifier la sortie avant d’agir ajoute une étape au flux de travail, au lieu d’en retirer une. Même si l’IA est précise, l’effet net est négatif. Les utilisateurs débordés, qui traitent les tickets à la chaîne, contourneront tout ce qui brise leur rythme.
La bonne approche de conception : une IA qui agit avant que l’utilisateur n’ait à y penser. Avec Hiver :
- Les e-mails sont étiquetés avant que les agents ne les ouvrent.
- Le sentiment est calculé et signalé avant qu’un agent n’ouvre la conversation : un client frustré est déjà remonté en tête de la file d’attente.
- L’ordre de la file d’attente reflète les signaux de priorité sans que les agents aient à configurer quoi que ce soit.
- Des brouillons de réponse apparaissent en ligne sous forme de suggestions.
- Les cas où la confiance du modèle tombe en dessous d’un seuil sont remontés pour révision humaine, plutôt que d’entraîner une action automatique.
L’interface n’est pas conçue autour de l’idée de demander de l’aide à l’IA. Les agents n’ont pas besoin de la déclencher. Les e-mails sont étiquetés et priorisés avant qu’ils ne les ouvrent. L’IA élimine des efforts avant même que l’agent n’ait à y penser.
La mesure interne pour savoir si cela fonctionne : « Si les utilisateurs remarquent l’IA, vous l’avez probablement mal conçue. »
Quand tout fonctionne, les utilisateurs ne parlent plus de la fonctionnalité IA. Ils mentionnent des temps de résolution plus rapides, un arriéré réduit, et une intégration facilitée pour les nouveaux agents. L’IA n’est plus visible, elle devient structurelle.
| 📌 Instantané client : comment cela se concrétise en pratique |
|---|
| Chez ITS Logistics, les équipes géraient les conversations clients sur des boîtes mail éparpillées, orientaient les demandes manuellement, et se gênaient souvent avec des réponses en double ou des relances oubliées. Après le passage à Hiver, cela a changé rapidement. En seulement trois semaines, le délai de réponse pour les devis a chuté de 61%, et la plupart des demandes entrantes étaient automatiquement acheminées vers la bonne personne. Plus important encore, chaque conversation avait un responsable clairement identifié, et les managers avaient enfin de la visibilité sur l’avancement du travail. Le résultat : un système capable de gérer une demande croissante sans ajouter de complexité ou d’effectifs, car le travail est devenu plus structuré et prévisible. « Hiver a transformé des questions dispersées en un service client organisé. Chaque demande est suivie, prise en charge et résolue plus vite. » — Alejandro Arboleda, Directeur des opérations, ITS Logistics. |
Précision et confiance sont deux problèmes différents
Un système peut afficher 95 % de précision et néanmoins échouer en production si les utilisateurs ne comprennent pas de façon fiable quand il peut se tromper.
La confiance découle de la prévisibilité et du contrôle. Les utilisateurs doivent comprendre le comportement du système suffisamment bien pour savoir quand s’y fier et quand passer outre. S'ils ne peuvent pas développer ce modèle mental, ils cesseront soit d’utiliser la fonctionnalité, soit de vérifier ses résultats : deux modes d’échec.
L’approche de Hiver consiste à faire de la correction une composante centrale de la conception et non un plan B en cas d’erreur. Les agents peuvent annuler toute prédiction en un seul clic. Le système capture les modifications comme signaux de retour. Les seuils basés sur la confiance décident de ce qui est appliqué automatiquement ou remonté pour vérification.
Pour citer Anurag, « Au lieu de voir les corrections comme des échecs, nous en avons fait des fonctionnalités. Cela garde le contrôle aux agents et crée un cercle vertueux sans jamais entraîner sur les données clients. Le système s’améliore en observant les résultats. »
Ce choix règle aussi un problème de données. Les corrections générées servent de retour d’information, de sorte que le modèle s’améliore à partir des résultats constatés, sans nécessiter l’accès aux données clients brutes.
La frontière de la confidentialité reste intacte pendant que le système devient plus précis avec le temps.
Deux questions avant de mettre en ligne une fonctionnalité d’IA
Avant de lancer une nouvelle fonctionnalité IA, posez-vous deux questions :
« Si cette fonctionnalité était supprimée demain, les utilisateurs se plaindraient-ils ? »
Si la réponse est non, la fonctionnalité est utile mais non essentielle. Elle n’a pas encore changé la manière de travailler. C’est ce niveau d’impact qui mérite vraiment d’être recherché.
« Cette fonctionnalité élimine-t-elle une décision ou en ajoute-t-elle une nouvelle ? »
Si les utilisateurs doivent décider de faire confiance à l’IA, de la configurer ou d’interpréter ses résultats avant d’agir, l’IA a ajouté une charge cognitive au lieu de l’alléger.
C’est un échec, quelle que soit la performance technique.
Le véritable travail derrière les fonctionnalités d’IA
Bâtir une IA performante en production relève moins du choix du modèle que du choix du problème, de l’évaluation de la faisabilité et de la conception en phase avec la façon de travailler réelle. L’IA en elle-même est la partie la plus mineure de l’équation.
« Le produit n’a jamais été la classification, l’analyse de sentiment, la rédaction ou le résumé. Le produit, c’était moins de décisions par agent, un résultat plus rapide, une charge cognitive réduite, des opérations évolutives. L’IA était le mécanisme, et ce mécanisme ne fonctionne que s'il s’applique au bon problème, avec des données réellement pertinentes. »
Si vous vous demandez comment intégrer l’IA dans vos opérations de support, parlons-en chez Hiver. Nous vous montrerons comment nous pouvons vous aider à offrir un service empathique.