How Does Sentiment Analysis Work?

You may already know that sentiment analysis is used to determine whether a piece of data has a neutral, positive or negative sentiment. But, since you’re here, chances are you don’t have much of a deeper understanding than that.
In this article, I’ll answer the questions: What is sentiment analysis? How does sentiment analysis work? And what can sentiment analysis do for you?
Once you’re all clued up, you can go on to check out our list of the 10 best sentiment analysis tools.
What Is Sentiment Analysis?
Before we dive in, a quick recap of what sentiment analysis is.
As humans, we use sentiment analysis daily to judge each other’s opinions. Sometimes it can be tricky, like when dealing with a particularly sardonic friend or trying to figure out how our boss really feels when giving feedback on a big presentation! Sentiment analysis software attempts to mimic this very human experience.
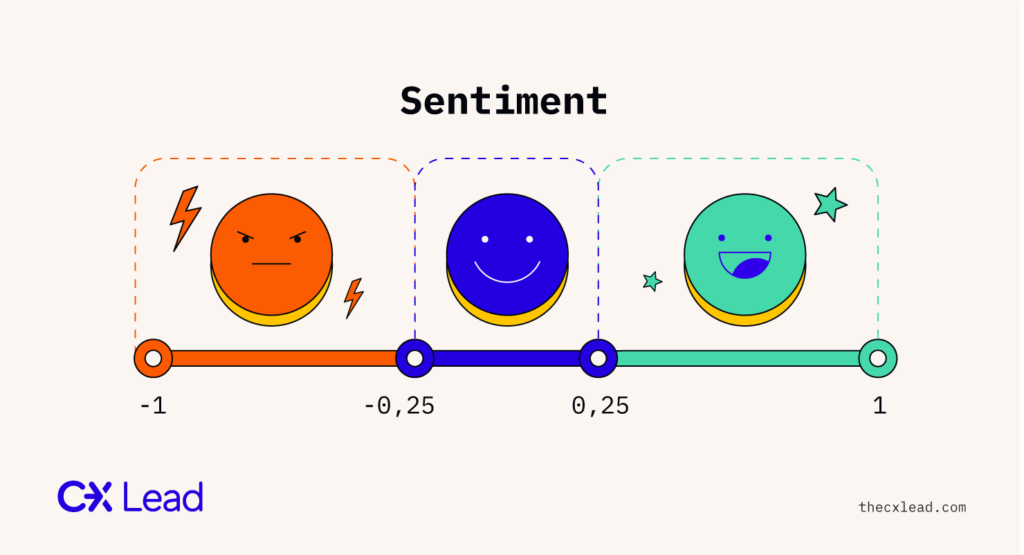
Although some software can analyze speech, most sentiment analysis tools are used for text analysis to classify the overall sentiment of a piece of text as positive, negative, or neutral. This is referred to as polarity.
Common sources of data for sentiment analysis are social media posts, news articles, online reviews, solicited feedback forms, survey responses, webpages/blogs/forums. You may also hear sentiment analysis referred to as opinion mining, emotion AI, or, more technically, sentiment classification.
There are four main types of sentiment analysis:
- Fine-grained aka polarity (positive, negative or neutral)
- Feelings and emotions (happy, angry, sad, amused)
- Aspect-based (identifies opinion on a specific aspect of something e.g. camera on a smartphone)
- Intent (interested, not interested, very interested).
Sentiment analysis tools help you pick through the vast quantity of subjective data available in web 2.0 to understand stakeholder feedback.
Organizations utilize sentiment in a number of ways. Many brands use it as part of their market research to better understand what in their brand strategy is working well and where they need to improve. Another use is by financial institutions to analyze the news cycle and identify investment opportunities.
How Does Sentiment Analysis Work?
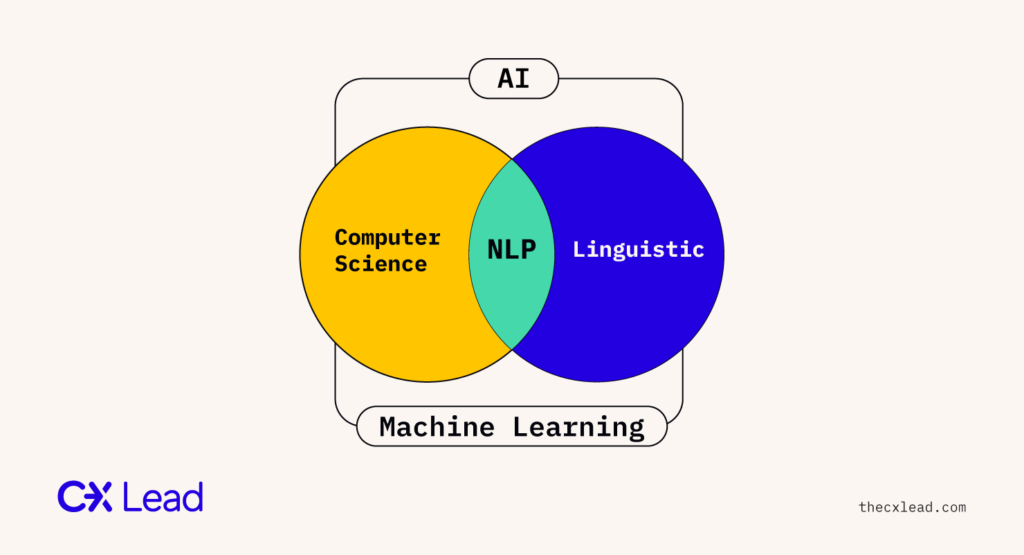
OK now let’s get into the mechanics of how sentiment analysis actually works. At its core, sentiment analysis is a form of data science. More specifically, it’s a form of natural language processing (NLP), itself a sub-branch of artificial intelligence (AI), for identifying and classifying subjective opinions from text or speech data.
AI in customer sentiment analysis exists right at the intersection of computer technology and human speech, an exciting prospect for any data scientist with a love of linguistics.
But it’s not easy. To properly understand the language within a text, and produce an accurate sentiment score or meaningful insight, programs must use a variety of methods that simulate what we as humans do intuitively. These simulations take the form of advanced algorithms (instructions for computers).
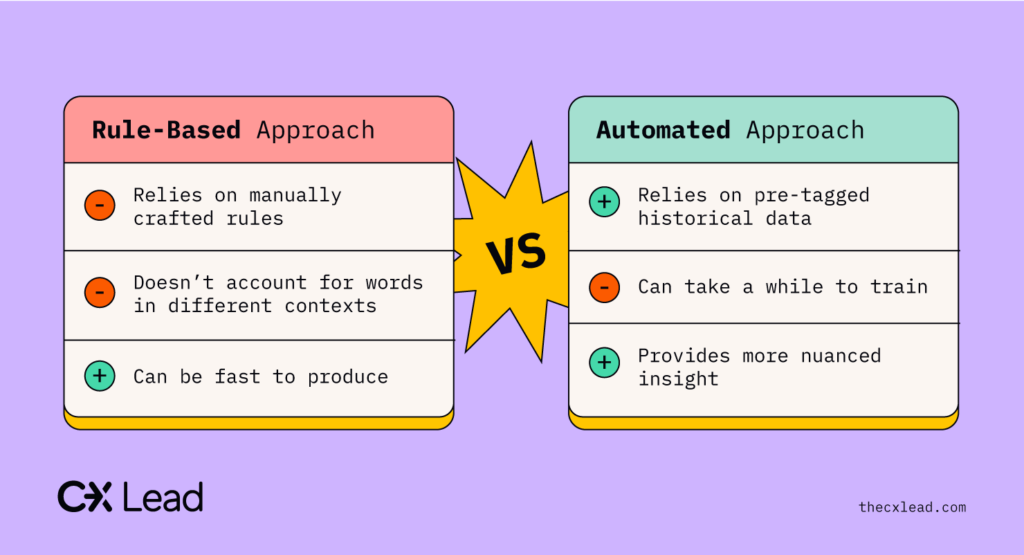
From here, there are two main approaches to sentiment analysis:
- Rule-based: a system based on rules that are manually established by humans.
- Automatic: systems that learn themselves using advanced machine learning techniques.
The fundamental difference between the two is their approach to teaching the system. We’ll now unpack these in a bit more detail.

Rule-based sentiment analysis
The rule-based method uses NLP alongside a set of manually defined rules to help identify subjectivity, polarity, or the subject of an opinion. Some of the NLP techniques used are stemming, tokenization, part of speech tagging, parsing and lexicon analysis. If you’re interested, you can read more about these here.
Here’s a basic example or rule-based sentiment analysis.
To determine the polarity of a piece of text, sentiment analysis tools must first break it down into individual components, i.e. words and phrases, using NLP. Then it runs these against a database, referred to as a lexicon or sentiment library, compiled from a collection of words and phrases that have been manually collected and scored.
Generally, neutral words and phrases are assigned a score of zero. Words that are significantly negative receive a negative score and positive words receive a positive score. For example, in a product review, words and phases like bad, disappointing, terrible, and horrible customer service would get negatively scored whereas good, great, helpful and useful would get scored positively.
Building a sentiment library and the corresponding rules is an extensive process. One must be careful to assign each word a score and also make apt comparisons. For example, the system needs to understand that “bad” is a negative word but “horrible” is even more negative; “good” is positive and “amazing” is even more positive.
The rule-based system can be fast to make but somewhat limited. This is because they can’t recognize words that don’t appear in the library or analyze words with respect to context—making it difficult to identify complexities like sarcasm, homonyms and polysemy. The phrase “call that excellent customer service?” could be easily misinterpreted, for example.
Rule-based systems also take a lot of effort to maintain and update. One must keep manually adding new rules to keep with the evolution of language online. Adding new rules also runs the risk of affecting previous results.
Automatic sentiment analysis
Rather than relying on a set of manually created and updated rules, automatic sentiment analysis systems are trained using machine learning techniques. In this case, machine learning refers to algorithms that use deep learning to become more accurate each time they hit a roadblock, require human intervention, or receive user feedback.
It gets technical, but here’s a simplified version of how it works.
- Find a large dataset that’s similar to the data you’d like to analyze and tag some examples. This becomes the training data. You’re not giving the system rules, you’re giving it examples.
- Use the training data to develop your machine learning model. This will consist of classification algorithms such as linear regression; naive bayes; support vector machines; RNN derivatives LSTM and GRU. As the name suggests, these are used to classify data (positive, negative, happy, sad, etc). If you’re interested, here’s some more information about these.
- If your model works, after being fed enough relevant data it will be capable of making its own predictions to classify previously unseen data. It’s identified its own rules!
- Keep improving the accuracy of these models by providing more examples.
The advantage of the automatic approach is the ability to adapt and create models trained for many different purposes and contexts.
For example, we know the word phoenix refers to a mythical bird and also the city of Phoenix in Arizona. A machine learning algorithm can be trained to identify, in context, which definition of Phoenix is meant when the word is used in a sentence. It can then use that experience to recognize similar cases.
Similarly, a model flags “woke” (meaning ‘to awaken’) as a neutral word. However, “woke” has recently become slang for “sociopolitically aware”, making it a freshly-minted homonym. Once the algorithm receives this feedback once, it can apply that new knowledge to every analysis going forward. The word “woke” now receives a positive-leaning score in certain contexts.
Automated methods are generally considered superior. However, the disadvantage of an automated approach based on machine learning is that they rely on having labeled historical data and can take a while to train. They also require highly skilled data scientists to develop!
Hybrid approach
Combining natural language processing with machine learning, referred to as a hybrid approach, is widely viewed to improve the accuracy of sentiment analysis. Natural language processing is used to understand word sentiment and parts of speech. Machine learning is used to deal with the constant evolution of language, view words in context, and figure out complex language processes like homonyms.
Applications of Sentiment Analysis
As mentioned, sentiment analysis is extremely useful for organizations who want to know how people feel about them. With so much data being created all the time, all over the world, sentiment analysis can help you make sense of it all in real-time.
Here are some of the ways this technology is already making a difference:
Responding to the Customer Experience
Customer experience feedback can be sourced organically on the web (social media mentions, for example) or from feedback that you actively solicit yourself. Hopefully there’s a large, varied dataset for you to work from. If so, this is where using sentiment analysis software can cover a lot of ground quickly and provide valuable insights. These can then be used in your reputation management efforts, inform product innovations and improve customer support.
Monitor Competitors
By monitoring the sentiment of your competitors, you can get a good grasp of their position in the market and compare it to your own. For example, say your Twitter mentions are 40 percent positive, 30 percent negative, and the rest neutral. How do you know if that’s good or not? Well, if your biggest competitor is somewhere around 60 percent positive, 30 percent negative, and the rest neutral, you have some work to do. If, on the other hand, sentiments are 50 percent negative, you know you’re doing okay according to industry standards.
Employee Experience
Lastly, sentiment analysis can help analyze data used by HR teams to understand what makes employees happy or why they’re leaving a company. By identifying common complaints and issues, employers get actionable insights into how to reduce turnover and improve employee performance. This capability is especially useful for companies with a lot of employees, as management would not have the time to speak to hundreds of staff members individually.
Is Sentiment Analysis Accurate?
As a lot of the sentiment analysis we do as humans is subjective, it’s unrealistic to expect a sentiment analysis tool to be accurate 100 percent of the time. Data scientists are getting better at developing more accurate sentiment classifiers, but there’s still a way to go.
What are the biggest challenges to a sentiment analysis model? We’ve already mentioned a few, and they’re the issues that make sentiment analysis difficult for people. The most common issues include:
- Sarcasm. If you’ve ever spent time in the comments section, or got a text message and you weren’t sure if the sender was serious, you know that sarcasm is hard to gauge in text. Consider the following two situations:
The train is only 30 minutes late again today. So glad it’s reliable!
The train is only 2 minutes late again today. So glad it’s reliable!
Obviously the train that’s 30 minutes late isn’t reliable, but sentiment analysis software might have a hard time picking up on that.
- Multipolarity. Sometimes, one sentence can speak positively to one thing and negatively to another. For example, “Pepsi is much better than Coke.” This sentence manages to say something positive about Pepsi and negative about Coke using only six words. A sentiment analysis system is unlikely to be able to accurately score this system without more sophisticated programming.
- Negations. A negation is when you reverse the meaning of a word or phrase, such as, “I wouldn’t say the food was good.” Us humans can have a difficult time figuring out the meaning of a phrase or sentence with a negation, so it’s unsurprising that sentiment analysis tools can struggle too.
Conclusion
Now you know all about sentiment analysis and how it can be used to analyze data to gauge customer opinion about your brand.
Sentiment analysis tools will do a lot of the heavy lifting for you, but it’s always wise to have a human look over some random samples of the work to check for things that machines have difficulty understanding. Sentiment analysis is most effective when technology and humans work hand-in-hand.
Looking for more customer experience insights? Subscribe to The CX Lead newsletter.
Related Read: 10 Best Customer Support Software For SMBs And Enterprises

{kind=link}