Was es braucht, um KI zu bauen, die im Kundenservice wirklich funktioniert (Einblicke vom Leiter KI bei Hiver)



Einblicke vom Leiter der KI bei Hiver
Die meisten Menschen gehen davon aus, dass die Entwicklung von KI-Funktionen für eine Kundenservice-Plattform lediglich Planung, Umsetzung und Auslieferung bedeutet.
Doch wer mit den Menschen hinter den Kulissen spricht, erkennt, wie anders die Realität tatsächlich ist.
Anurag Maherchandani, Leiter der KI bei Hiver, ist einer dieser Menschen. Bei Hiver, einer KI-gestützten Kundenservice-Plattform, die von über 10.000 Support-Teams genutzt wird, um Kundengespräche in großem Maßstab zu bearbeiten, war der Druck, „KI hinzuzufügen“, früh und heftig zu spüren. Jeder Posteingang, jedes Ticket und jede Kundeninteraktion schien ein natürlicher Kandidat für Automatisierung zu sein.
 , Leiter der KI bei Hiver, ist einer dieser Menschen. Bei
, Leiter der KI bei Hiver, ist einer dieser Menschen. Bei {kind=link}
Anurag leitet sämtliche KI-Initiativen von Hiver, was bedeutet, dass er dafür verantwortlich ist, herauszufinden, was gebaut werden soll, wie es gebaut wird und warum es für die Kunden relevant sein sollte. Hier ist seine Sichtweise darauf, was wirklich nötig ist, um funktionierende KI-Funktionen zu entwickeln.
Beginnen Sie mit dem Ergebnis, nicht mit dem Modell
Das zentrale Prinzip hinter jeder KI-Entscheidung bei Hiver: KI ist nicht das Produkt. Das Ergebnis ist das Produkt.
In der Praxis bedeutet das, dass der Ausgangspunkt für jede KI-Funktion niemals „Was kann dieses Modell?“ ist, sondern „Wo verbringen Menschen Zeit mit Entscheidungen, die sie nicht treffen müssten?“
Diese Unterscheidung prägt alles Weitere, von der Auswahl des Problems bis hin zur Art und Weise, wie die Funktion in der Benutzeroberfläche dargestellt wird.
„Wenn Teams sagen, sie bauen ein ‚KI-Produkt‘, meinen sie meist, dass sie ein Modell integriert, es durch eine Benutzeroberfläche verfügbar gemacht und hohe Genauigkeitswerte erreicht haben. Aber nichts davon garantiert echten Wert. Nutzer kaufen keine Intelligenz. Sie kaufen Erleichterung: von repetitiver Arbeit, von Unsicherheit, von operativen Reibungen,“ sagt Anurag.
Selbst wenn ein Modell im Test hervorragend abschneidet, ist die entscheidende Bewährungsprobe, ob es die Art und Weise beeinflusst, wie die Nutzer arbeiten.
Inference oder Regeln: Wählen Sie zuerst das richtige Werkzeug
Bevor ein Problem die Phase der Modellauswahl oder Datenauswertung erreicht, gibt es eine grundlegendere Frage: Ist hier wirklich Inferenz notwendig?
Inference bedeutet, dass das System aus Mustern, die es nicht explizit gesehen hat, verallgemeinern und Urteile fällen muss, die im Vorfeld nicht vollständig abbildbar sind.
Regeln bedeuten, dass die Logik explizit niedergeschrieben werden kann: Wenn X, dann Y. Die beiden Ansätze sind nicht austauschbar, und Inferenz einzusetzen, wenn Regeln ausreichen würden, bedeutet zusätzliche Kosten, Verzögerungen und Unvorhersehbarkeit – ohne Mehrwert.
Als das Team von Hiver das Routing für E-Mails aus bestimmten Kundensegmenten wie VIP-Konten, bestimmten Branchen oder Domains einrichten musste, war der erste Impuls, ein KI-Modell zu bauen, das sie automatisch erkennt.
Stattdessen entwickelte Hiver konfigurierbare Regelobjekte. Diese nutzen explizite Logik basierend auf Domains, Schlüsselwörtern und Metadaten. Das Ergebnis ist vorhersehbar, einfach zu debuggen und kann vom Endbenutzer konfiguriert werden, ohne das KI-Team von Hiver einzubinden.
Möchte ein Unternehmen beispielsweise, dass alle E-Mails von @enterprise.com oder Nachrichten mit dem Wort „Vertrag“ in die Prioritäts-Inbox gelangen, kann es eine Regel innerhalb von Minuten erstellen. Dafür braucht es keine KI, und es gibt keinerlei Unklarheit, wie E-Mails behandelt werden.
Wie Anurag es ausdrückt: „Wenn Sie die Regeln schreiben können, dann schreiben Sie die Regeln. Heben Sie KI für Probleme auf, bei denen Regeln unmöglich aufzuzählen wären – wo das System aus Mustern verallgemeinern muss, die es noch nie explizit gesehen hat.“
Bewertung von Problemen, die tatsächlich Inferenz erfordern
Wenn ein Problem tatsächlich Inferenz benötigt, prüft Hiver es anhand von vier Kriterien, bevor die Umsetzung in Angriff genommen wird:
- Häufigkeit. KI verursacht echten Mehraufwand: Inferenzkosten, zusätzliche Latenz und unvorhersehbare Fehlerquellen. Dieser Mehraufwand lohnt sich nur, wenn die Aufgabe häufig genug ist, damit sich Automatisierung auszahlt. Eine Aufgabe, die nur ein paar Mal pro Woche anfällt, rechtfertigt selten die Komplexität. Eine Aufgabe, die Agenten Hunderte Male pro Tag erledigen, dagegen schon.
- Vorhersehbarkeit. Manche Klassifikationen stützen sich auf Informationen, die direkt im Input enthalten sind (E-Mail-Inhalt, Betreffzeile, Metadaten), anstatt aus verfügbaren Daten zu lernen. Andere benötigen Kontext, den das Modell einfach nicht hat: Kundenstatus, interne Eskalationsrichtlinien, mit der Zeit aufgebautes Agentenurteil. Bevor die Entwicklung beginnt, prüft das Team mithilfe historischer Daten die Umsetzbarkeit und ob eine Vorhersage überhaupt mit brauchbarer Wahrscheinlichkeit möglich ist. Ist kein Signal vorhanden, ändert auch keine Architekturentscheidung etwas daran.
- Kundenbedarf. Wird hier ein Problem gelöst, das Kunden selbst benannt haben – oder eines, das das Team ihnen lediglich unterstellt? Ersteres hat eine viel höhere Wahrscheinlichkeit, übernommen zu werden. Letzteres produziert Features, die zwar funktionieren, bei der tatsächlichen Nutzung aber häufig ignoriert werden.
- Bedeutung und Umkehrbarkeit. Was passiert, wenn das Modell falschliegt? Ein falsch zugeordneter Tag, den ein Agent mit einem Klick korrigieren kann, ist deutlich weniger risikobehaftet als eine fehlgeleitete Antwort an einen Kunden oder eine verpasste Eskalation. Vorhersagen mit geringem Risiko und einfacher Rückgängigmachung sind beste Kandidaten für Automatisierung. Entscheidungen mit hohem Risiko benötigen entweder menschliche Kontrolle oder deutlich höhere Schwellen bei der Zuverlässigkeit, bevor sie ausgelöst werden.
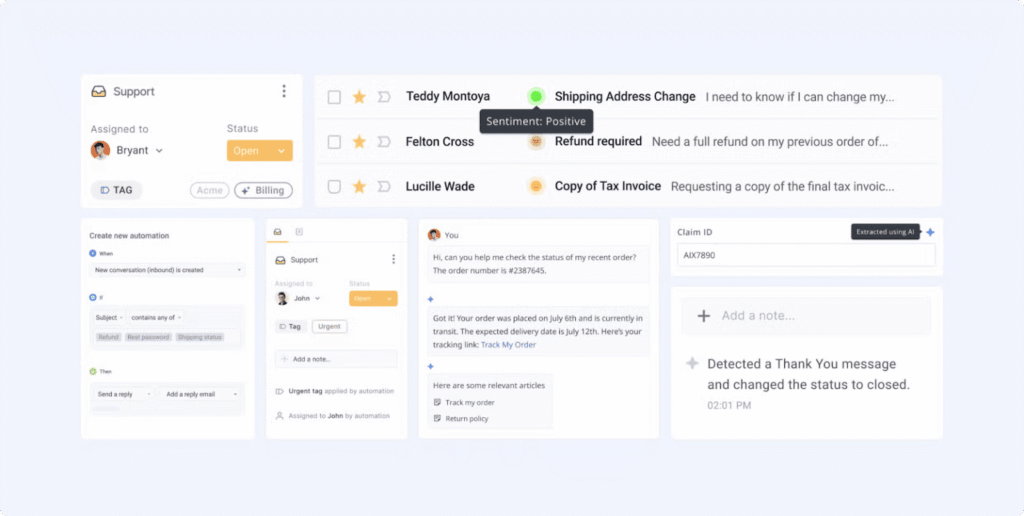
Das Auto-Tagging-Feature von Hiver funktioniert, weil es alle vier Kriterien erfüllt. Es nutzt ein Modell, um den relevantesten Tag für eine eingehende Konversation zu bestimmen. Agent:innen müssen jedes Ticket nicht mehr einzeln manuell kategorisieren.
Teams definieren im Administrationsbereich eine Menge von Tags wie „Abrechnung“ oder „Technischer Support“. Diese dienen als Zielvorgaben für die Vorhersage. Das Modell lernt Muster aus dem E-Mail-Inhalt, der Betreffzeile und den Metadaten. Es werden nur Tags mit klaren Signalstrukturen einbezogen.
Agent:innen führen diese Aufgabe bei nahezu jeder Konversation aus, was sie sehr häufig macht. Das Signal ist im E-Mail-Inhalt für die einbezogenen Tags vorhanden, was sie vorhersagbar macht. Hiver-Kunden haben explizit verlangt, die manuelle Vorsortierung zu reduzieren, was die Übernahme fördert. Wenn das Modell falsch liegt, kann der Tag mit einem Klick korrigiert werden – das Risiko bleibt dadurch niedrig und umkehrbar.
Sentiment-Analyse folgt demselben Muster. Sie analysiert den Tonfall jeder Konversation, um zu erkennen, ob ein Kunde verärgert, neutral oder positiv gestimmt ist. Da dies bei jeder Konversation geschieht, ist es sehr häufig. Der Ton ist im Text enthalten und damit vorhersagbar.
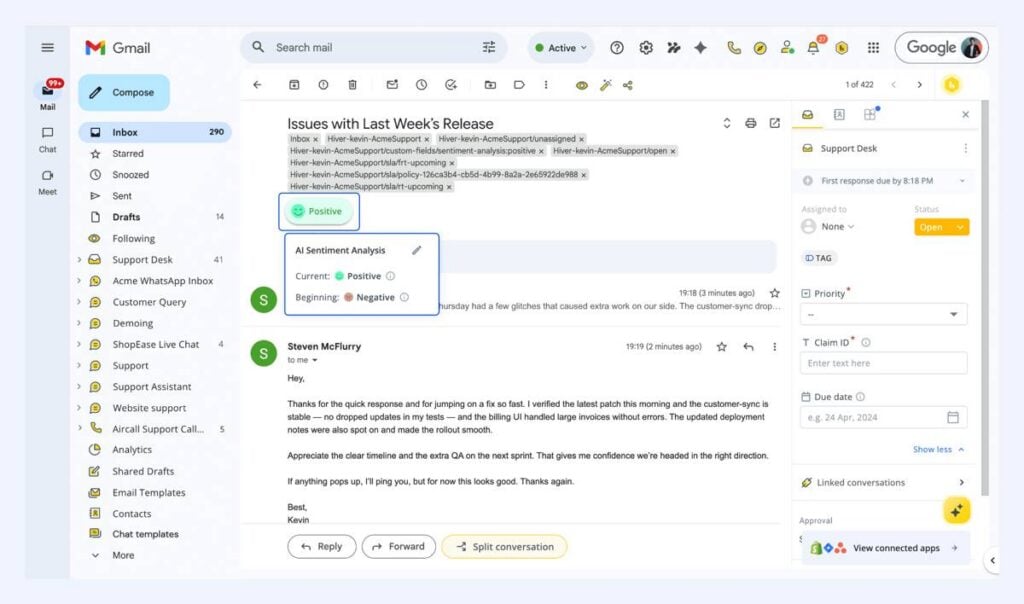
Teams wünschen sich frühzeitige Sicht auf unzufriedene Kunden – dadurch entsteht eine klare Nachfrage. Liegt das Modell falsch, können Agent:innen es überstimmen, ohne das Ergebnis zu beeinflussen, wodurch das Risiko gering bleibt.
Machbarkeitsprüfung vor der Entwicklung
Einer der disziplinintensivsten Teile des Hiver-Prozesses: Genauigkeits- und Machbarkeits-Tests, bevor Produktionscode geschrieben wird.
Die Tag-Vorschlagsfunktion ist dafür ein anschauliches Beispiel. Wenn eine E-Mail beispielsweise lautet: „Mir wurde zweimal abgebucht,“ sollte das Modell „Abrechnung“ auswählen. Das Modell versuchte aber auch, Tags wie „VIP-Kunde“ oder „An Manager eskalieren“ zu vergeben, die nicht allein aus der E-Mail herzuleiten sind. Die Genauigkeit war schlecht und die Agent:innen haben dem Ergebnis nicht mehr vertraut.
Das zugrundeliegende Problem war es, zwischen vorhersagbaren und nicht vorhersagbaren Tag-Typen zu unterscheiden. Kategorietags wie „Abrechnung,“ „Technischer Support,“ und „Retouren“ lassen sich auf sprachliche Muster im E-Mail-Text abbilden. Sie sind erlernbar.
Operationale Tags wie „VIP-Kunde,“ „Warten auf Rechtsabteilung,“ und „An Manager eskalieren“ hängen von Kontext außerhalb des Inputs ab: Kontohistorie, interne Geschäftsregeln, teamübergreifende Koordination. Kein Modell, das mit Kund:innen-E-Mails trainiert wurde, kann sie zuverlässig vorhersagen.
Die Lösung war strukturell: Bevor ein Tag-Typ Ziel einer Vorhersage wird, durchläuft er einen Machbarkeitscheck. Unterstützen historische Daten eine verlässliche Vorhersage dieses Ergebnisses? Wenn nicht, wird er aus dem Modell ausgeschlossen – egal wie nützlich eine Automatisierung dieses Tags theoretisch wäre.
„Die Disziplin, zu sagen: 'Dieser Tag-Typ eignet sich nicht zur Automatisierung,' war schwieriger als das Modell zu bauen. Aber so haben wir nur Vorhersagen ausgeliefert, denen Agent:innen vertrauen konnten.“
KI in den Workflow einbetten, nicht obenauf setzen
Wo KI im Produkt verankert ist, ist mindestens so wichtig wie das, was sie tut.
Eine Funktion, die Nutzer:innen dazu bringt, innezuhalten, einen Prompt einzugeben und das Ergebnis zu prüfen, fügt dem Workflow einen Schritt hinzu – statt einen zu entfernen. Das ist ein Netto-Nachteil, selbst wenn die KI akkurat arbeitet. Nutzer:innen, die schnell arbeiten und Ticket nach Ticket abarbeiten, umgehen alles, was diesen Rhythmus unterbricht.
Das erfolgversprechende Designprinzip: KI, die agiert, bevor Nutzer:innen überhaupt darüber nachdenken müssen. Bei Hiver:
- E-Mails werden markiert, bevor die Mitarbeitenden sie öffnen.
- Stimmungen werden berechnet und markiert, bevor ein Mitarbeitender das Gespräch öffnet: Ein frustrierter Kunde steht bereits ganz oben in der Warteschlange.
- Die Reihenfolge in der Warteschlange spiegelt Prioritätssignale wider, ohne dass die Mitarbeitenden etwas konfigurieren müssen.
- Antwortentwürfe erscheinen direkt als Vorschläge.
- Fälle, in denen das Modell unter eine Vertrauensschwelle fällt, werden für menschliche Überprüfung hervorgehoben, anstatt automatisch gehandhabt zu werden.
Die Benutzeroberfläche ist nicht darauf ausgelegt, dass man die KI aktiv um Hilfe bittet. Die Mitarbeitenden müssen sie nicht auslösen. E-Mails werden markiert und priorisiert, bevor sie geöffnet werden. Die KI nimmt Arbeit ab, bevor sich ein Mensch damit beschäftigen muss.
Das interne Maß dafür, ob das funktioniert: „Wenn Nutzer die KI bemerken, haben Sie sie wahrscheinlich falsch gebaut.“
Wenn sie funktioniert, sprechen die Nutzer nicht mehr über die KI-Funktion. Sie sprechen von kürzeren Lösungszeiten, weniger Rückstau, einfacherer Einarbeitung neuer Mitarbeitender. Die KI ist von einer sichtbaren zu einer strukturellen Komponente geworden.
| 📌 Kundenbeispiel: So sieht das in der Praxis aus |
|---|
| Bei ITS Logistics managten die Teams Kundenanfragen über verstreute Postfächer, leiteten Anfragen manuell weiter und kamen sich mit doppelten Antworten oder verpassten Follow-ups oft in die Quere. Nach dem Wechsel zu Hiver änderte sich das schnell. Bereits nach nur drei Wochen sank die Angebotsdurchlaufzeit um 61 %, und die meisten eingehenden Anfragen wurden automatisch an die richtige Person weitergeleitet. Noch wichtiger: Jede Unterhaltung hatte eine klare Zuständigkeit, und Manager hatten endlich Einsicht in den Arbeitsfortschritt. So entstand ein System, das wachsenden Anforderungen Stand halten konnte, ohne Komplexität oder Personalaufwand zu erhöhen – denn die Arbeit selbst wurde strukturierter und vorhersehbarer. „Hiver hat verstreute Anfragen in ein strukturiertes Kundenservice-System verwandelt. Jede Anfrage wird nachverfolgt, verantwortet und schneller gelöst.“ — Alejandro Arboleda, Operations Director, ITS Logistics. |
Genauigkeit und Vertrauen sind verschiedene Herausforderungen
Ein System kann 95 % Genauigkeit erreichen und in der Praxis trotzdem scheitern, wenn die Benutzer kein zuverlässiges mentales Modell davon haben, wann es Fehler macht.
Vertrauen entsteht durch Vorhersehbarkeit und Kontrolle. Nutzer müssen das Verhalten des Systems so gut verstehen, dass sie wissen, wann sie sich darauf verlassen können und wann sie eingreifen sollten. Wenn sie dieses Modell nicht entwickeln können, nutzen sie entweder die Funktion nicht mehr oder überprüfen deren Ergebnisse nicht mehr – beides ist gescheitert.
Hivers Ansatz ist, Korrekturen als zentralen Teil des Designs zu verstehen, statt sie als Notlösung für Fehler zu betrachten. Mitarbeitende können jede Vorhersage mit nur einem Klick überstimmen. Das System erfasst Korrekturen als Feedbacksignale. Schwellenwerte auf Basis der Zuverlässigkeit bestimmen, was automatisch übernommen wird und was zur Überprüfung angezeigt wird.
In Anurags Worten: „Anstatt Überschreibungen als Fehler zu betrachten, haben wir sie als Feature eingebaut. So behalten die Mitarbeitenden die Kontrolle und es entsteht ein Lernkreislauf, ohne dass wir je mit Kundendaten trainieren. Das System wird besser, indem es die Ergebnisse beobachtet.“
Damit wird auch ein Datenproblem gelöst. Weil Korrekturen als Feedbacksignale zurückfließen, verbessert sich das Modell durch beobachtete Ergebnisse und benötigt keinen Zugriff auf Rohdaten der Kundenkommunikation.
Die Datenschutzgrenze bleibt gewahrt, während das System im Lauf der Zeit immer präziser wird.
Zwei Fragen, bevor jede KI-Funktion startet
Vor der Freigabe einer neuen KI-Funktion gibt es zwei Fragen:
„Würden sich Nutzer beschweren, wenn diese Funktion morgen entfernt würde?“
Wenn die Antwort Nein lautet, ist die Funktion zwar ein Mehrwert, aber nicht essenziell. Sie hat die Arbeitsweise der Menschen noch nicht verändert. Nur darauf lohnt es sich hinzuarbeiten.
„Reduziert diese Funktion eine Entscheidung – oder schafft sie eine neue?“
Wenn Nutzer erst entscheiden müssen, ob sie der KI vertrauen, sie konfigurieren oder ihre Ergebnisse interpretieren sollten, bevor sie handeln, dann hat die KI eher mentale Belastung geschaffen als sie zu reduzieren.
Das ist ein Scheitern – auch wenn die Technik einwandfrei funktioniert.
Die eigentliche Arbeit hinter KI-Funktionen
KI, die im Alltag wirklich funktioniert, entsteht weniger durch die Auswahl eines Modells, sondern durch die richtige Problemauswahl, Machbarkeitstests und die Ausrichtung auf reale Arbeitsprozesse. Die KI selbst ist der kleinste Teil der Herausforderung.
„Das Produkt war nie Klassifizierung, Sentiment-Analyse, Entwurfs- oder Zusammenfassungsfunktion. Das Produkt waren weniger Entscheidungen pro Mitarbeitenden, schnellere Ergebnisse, geringere mentale Belastung, skalierbare Abläufe. KI war der Mechanismus – und der funktioniert nur, wenn er auf das richtige Problem angewandt wird, das durch die tatsächlichen Daten auch lösbar ist.“
Wenn Sie darüber nachdenken, wie KI in Ihr Support-Team passt, sprechen Sie mit uns bei Hiver. Wir zeigen Ihnen, wie wir Sie dabei unterstützen können, einen empathischen Support zu bieten.